AI coding agents are now standard infrastructure. GitHub Copilot alone has over 1.8 million paid users. The recurring failure mode is not model quality — it is retrieval: keyword overlap picks files, the agent ingests the whole bundle, and nobody checks which files actually shaped the answer.
The problem
Pose a question about middleware ordering in a monorepo with thousands of modules. Retrieval hands back a dozen paths; two matter, the rest are cargo. The agent still tokenizes every path you sent — you pay for the bundle, and noise can steer the model toward a plausible-but-wrong edit.
This is not a tuning problem. It is structural. Developers write issue reports in natural language: behavior, intent, symptoms. Source code is written for compilers: identifiers, control flow, type annotations. BM25 matches tokens, not meaning. Ask why "retries never back off under load" and BM25 may never surface utils/retry_policy.py even when that module owns the bug.
Worse: retrieval rarely learns from outcomes. A bad page that keeps ranking highly stays in rotation. Static indexes do not tell you which context the model ignored — there is no health metric and no repair trigger.
Why now
Three things converged to make this possible and necessary at the same time.
Long-context models made naive retrieval expensive. At 4K tokens, agents retrieved 3 files. At 128K, they retrieve 15–20 — and bill for all of them. The cost of careless retrieval scaled with the capability improvement.
Agents went from experiment to infrastructure. Organizations run thousands of agent queries per day. At that volume, a 60× token inefficiency is a line item, not a rounding error.
LLMs can now write accurate prose summaries. The wiki generation step — summarizing a source file into useful natural language — required a quality threshold that only became reliably achievable in 2024–2025.
What Provenant does
Provenant builds a wiki layer once per repo: each file becomes a short LLM-written summary in plain English. Search runs on that prose, so queries meet descriptions instead of identifier soup.
Each answer carries citations. Provenant compares cited wiki pages to the pages it retrieved — that fraction is attribution confidence. When confidence sags, only the ignored pages are queued for rewrite in the background while the user keeps working.
Architecture
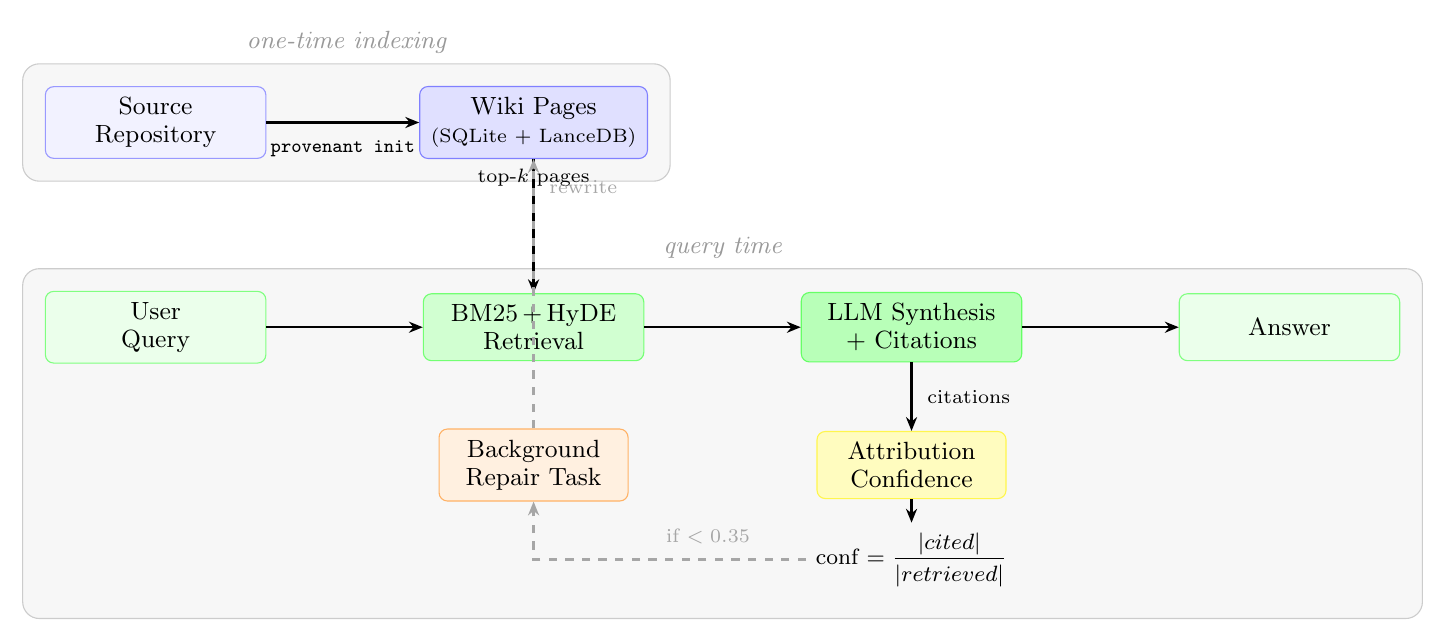
Wiki generation
Run provenant init once. Tree-sitter pulls symbols, imports, and layout; DeepSeek-V3.2 turns that skeleton into a wiki entry covering intent, public surface, important types/functions, and neighbours worth knowing about.
Pages live in two indices: SQLite FTS5 for BM25, and LanceDB with 768-dimensional embeddings (nomic-embed-text-v1.5 via Fireworks AI) for semantic search. A 70-page Flask-scale index costs approximately $0.05 and takes under two minutes.
Retrieval: BM25 and HyDE
Day-to-day retrieval is BM25 on wiki titles and bodies. When semantic lift is worth the cost, HyDE asks the model to draft a fake mini-answer, embeds that draft, and pulls vector neighbours. Lists are fused with Reciprocal Rank Fusion (k=60), then a lightweight reranker boosts pages whose wording actually overlaps the question before synthesis sees top-k.
HyDE is gated — it runs only when vector similarity crosses a bar. On 768-dim embeddings that happened on 15 of 500 SWE-bench Verified tasks (~3%), mostly in django, and those runs picked up Coverage@10 where they fired.
Attribution confidence
After synthesis:
High confidence: the answer leaned on what you fetched. Low confidence: lots of retrieved pages, few citations — either irrelevant context or muddy summaries. Log it per query and you get a cheap dashboard instead of batch-judging everything.
Automatic self-healing
Below confidence 0.35, repair runs asynchronously — the user-facing answer is not blocked. Each skipped citation reloads its source and gets a targeted rewrite prompt: the page was fetched but unused; tighten scope and align wording with the file on disk. Updates land in SQLite FTS and LanceDB; each page cools down for 300s so bursts of similar questions do not thrash the same entry.
asyncio.create_task(_bg_repair(uncited))Repairs never touch cited pages. In our Django run (1,393 wiki pages), the worst batch flagged 10 uncited entries — 0.7% of the index. One cycle cost about two cents, not a re-index bill.
Benchmark results
Evaluations target SWE-bench Verified file localisation: 500 merged issues across 12 Python codebases, each with gold files from the accepted patch. The question is whether retrieval surfaces a touched file in the top ranks — not patch generation or test runs.
Headline metric: Coverage@k — share of tasks with any gold path in the top-k predictions. MRR is reported where noted.
File localization
| Method | C@5 | C@10 | MRR |
|---|---|---|---|
| Raw BM25 on source files | 56.2% | 69.0% | 0.404 |
| Provenant BM25-on-wiki | 63.8% | 70.8% | 0.447 |
| + reranker + selective HyDE | 66.2% | 75.2% | 0.454 |
Raw file BM25: 56.2% C@5. Wiki BM25: 63.8% — +7.6 points on the same 500 tasks. C@10 inches up less because the win is ranking: the right file shows up higher, not just inside the top ten.
Per-repository breakdown
| Repository | N | BM25 wiki C@10 | +rerank +HyDE | ΔC@10 |
|---|---|---|---|---|
| astropy | 22 | 72.7% | 86.4% | +13.7 |
| pytest | 19 | 57.9% | 68.4% | +10.5 |
| pylint | 10 | 60.0% | 70.0% | +10.0 |
| sphinx | 44 | 45.5% | 52.3% | +6.8 |
| django | 231 | 74.0% | 79.2% | +5.2 |
| sklearn | 32 | 53.1% | 56.2% | +3.1 |
| matplotlib | 34 | 85.3% | 88.2% | +2.9 |
| sympy | 75 | 74.7% | 76.0% | +1.3 |
| xarray | 22 | 81.8% | 77.3% | −4.5 |
Eight of nine repos improve. HyDE only fired in django. On astropy (+13.7 C@10) and pytest (+10.5), reranking alone did the work — useful if you do not want embedding infra on day one.
xarray regressed (−4.5 C@10): tickets already name DataArray-class symbols; vector search added plausible neighbours that were not in the patch. Per-repo gates are the obvious fix.
Token efficiency
| Repository | Wiki tokens/query | Naive tokens/query | Reduction |
|---|---|---|---|
| Flask (30 questions) | 1,070 | 69,044 | 64.5× |
| Django (20 questions) | 994 | 59,634 | 60.0× |
Roughly 400 lines of source become a ~150-token wiki page. Blind judge on 20 Django Qs: mean score delta −0.15 (wiki vs full files), eight ties. That is judge noise, not a quality collapse — while input tokens fall 60–65×.
Attribution confidence as a quality signal
| Confidence bucket | N | Avg quality (1–5) |
|---|---|---|
| Low (0.0–0.2) | 4 | 4.50 |
| Mid (0.4–0.6) | 9 | 4.89 |
| High (0.8–1.0) | 7 | 5.00 |
Self-healing: early results
We exercised repair on the four lowest-confidence Django items — 10 pages rewritten (0.7% of index), ~$0.02 total, then re-queried.
| Query topic | Conf before | Conf after | Quality before | Quality after |
|---|---|---|---|---|
| Signal dispatch | 0.20 | 0.40 | 4 | 5 |
| Transactions | 0.20 | 0.20 | 5 | 5 |
| Test client | 0.20 | 0.40 | 5 | 4 |
| F() expressions | 0.20 | 0.20 | 4 | 5 |
| Average | 0.20 | 0.30 | 4.50 | 4.75 |
Why wiki retrieval generalizes
Gains track how far issue prose drifts from symbol names. Documentation-heavy trackers (sphinx, pylint, pytest) jump the most; codebases where tickets already name APIs (sympy, xarray) move less because keyword search was never starving.
Think of three dialects: executable source, human ticket text, and the wiki bridge written for search. Provenant lives in the third dialect so BM25 stops guessing identifiers it never saw in the question.
xarray's −4.5 C@10 slip is the mirror case: shared tokens like DataArray already align tickets and code, so extra semantic retrieval invited look-alike modules that were not in the patch. Repo-specific gates for HyDE should claw that back without dulling django-sized wins.
The self-improving index
Pair citation-derived confidence with surgical repair and you get a self-improving codebase index: every question leaves a trace of which summaries helped, and only the ignored summaries get rewritten.
Nightly full re-indexes throw away good pages and scale with repo size. Provenant's loop edits the ~0.7% with evidence of failure, spends cents per cycle, and wakes up only when confidence says something was off.
Hot paths see more queries, more citation signal, and faster polish; cold files stay untouched until someone asks. Usage and retrieval quality drift in the same direction instead of rotting evenly.
vs. existing tools
| Copilot / Cursor | Sourcegraph Cody | Provenant | |
|---|---|---|---|
| Retrieval over | Raw source | Raw source | LLM wiki pages |
| Attribution signal | ✗ | ✗ | ✓ |
| Self-healing index | ✗ | ✗ | ✓ |
| Token efficiency | Baseline | Baseline | 60–65× less |
| Works without embeddings | ✓ | ✗ | ✓ |
Treat Provenant as a plug-in retrieval plane: stack it under Copilot, Cursor, or Cody rather than ripping them out.
Cost & scale
| Action | Cost | Time |
|---|---|---|
| Index Flask (70 files) | $0.05 | < 2 min |
| Index Django (1,393 files) | ~$1.00 | ~25 min |
| Per query — Provenant (wiki) | ~$0.002 | — |
| Per query — naive full-file | ~$0.13 | — |
| Repair cycle (10 pages) | ~$0.02 | background |
MCP tools
Provenant exposes capabilities as MCP tools — callable from Claude Code, Cursor, and any MCP-compatible agent.
| Tool | Description |
|---|---|
provenant_ask | Answer a natural language question about the repository |
provenant_context | Retrieve wiki context for specific files or symbols |
provenant_search | Search wiki pages by keyword or semantic query |
provenant_dead_code | Identify unreferenced files and symbols |
provenant_risk | Assess change risk for a given file |
provenant_why | Explain why a file was retrieved for a query |
provenant_overview | High-level repository summary |
provenant_symbol | Look up a specific function, class, or constant |
Repair evidence is still thin: one large repo, twenty judged questions. Confidence scores grounding via citations, not truth. HyDE costs an extra model call on ~3% of traffic. Bad init-time summaries cap retrieval until repair catches them.
Stack
| Component | Technology |
|---|---|
| Parsing | tree-sitter |
| BM25 index | SQLite FTS5 |
| Vector store | LanceDB (768-dim) |
| Embeddings | nomic-embed-text-v1.5 via Fireworks AI |
| Synthesis | DeepSeek-V3.2 |
| Async repair | Python asyncio |
| Web UI | Next.js |
| API | FastAPI |
| LLM routing | LiteLLM |
Getting started
# Index a repository
provenant init /path/to/your/repo
# Ask a question
provenant ask "where is upload validation enforced?"The live prototype runs against pallets/flask — fully indexed and queryable. Provenant ships as an MCP server alongside any agent that supports the Model Context Protocol.
Use it, measure citations, let the weak pages heal. Token spend falls 60–65× with judge scores barely moving — that is the economic case. The technical case is file localisation, live attribution, and repair that touches less than 1% of the index per cycle.